| Su | Mo | Tu | We | Th | Fr | Sa |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
In 1935 J.H. de Boer gave a scientific presentation in England. He had been applying recent discoveries in the understanding of interatomic forces to the study of the cohesive properties of molecular crystals, the strength or inorganic materials, and the conformational analysis of polystyrene. In 1936 de Boer's paper, a forerunner of modern atomistic simulation studies, was published (see.), and it fascinating to see that after de Boer's talk, Professor Lennard-Jones remarked:
'While I agree that Van der Waals fields play an important role in the phenomena discussed by Dr. de Boer and that it is very desirable to estimate their magnitude, I should like to ask the author whether he thinks the theory sufficiently developed at present to make reliable quantitative calculations. I think the formula given by London was intended only for spherically symmetrical systems and even then it is only approximate. While it gives the right order of magnitude for the inert gases, it is not yet certain that there is not an error by a factor of two. But the error may he greater in the case of aromatic molecules owing to their lack of symmetry and to their special electronic structure in that they contain "non-localized" electrons. Is it not likely that these will require special treatment?
de Boer replied to Lennard-Jones that comparison between experiment and theory provided justification for the approach. A nice pragmatic response from one of the earliest practitioners of materials science atomistic simulation.
One cannot help but think that Professor Lennard-Jones might be surprised to learn today that many scientists now blithely trust potential descriptions of the types employed by de Boer without a second thought, and that frequently these potentials bear the name 'Lennard-Jones'....and, additionally, reliability of these potentials has been shown to be substantially better than Lennard-Jones feared.
I have needed to make online demonstration videos recently. The strategy I have come up with for this, which seems to avoid too much rework, and yields a reasonable quality video is:
1. Use GotoMeeting in 'record' mode to capture the video
2. GotoMeeting uses a proprietary capture format - but this can be converted to a normal .wmv file with:
g2mtranscoder.exe source=c:\video.wmv
3. View the video and record a voice over with 'Audacity' saving the audio in mp3 format
4. Merge the audio and video with:
ffmpeg -i video.wmv -i audio.mp3 -acodec copy -vcodec copy -map 0:1 -map 1:0 output.wmv
In the final step the -map options may need to be adjusted, depending on the way the video file is created by the GotoMeeting session
I try to make the recording in a single take, to avoid large scale editing, which is tedious. This overall strategy results in videos which are high enough in quality for the text in dialog boxes to be visible (which is important in training videos) but with manageable file sizes.
I have had occasion to scan a few papers to PDF format recently. Typically this produces large PDF files, because many bytes are used to represent the RGB value of the pixels of the document image. Of course, the original document is generally black and white, and the faithful representation of its coloring is pointless and makes the PDF file larger than it can be.
So I made a little script which takes a PDF file written by the scanning program and 'monochromizes' it.
Here is the script - it uses various image processing commands from the Linux world. It is not 'fancy', just utilitarian - use at your owk risk! The reduction in size of the PDF file can be significant - so if you are struggling with overly large PDFs, this script (or your own modification to it) may be of value.
#!/bin/sh
NPAGES=`pdftk $1 dump_data | grep NumberOfPages | awk '{print $2}'`
OUTPUTFILE=`basename $1 .pdf`.bw.pdf
i=0
while [ $i -lt $NPAGES ]
do
i=`expr $i + 1`
echo $i
d=`echo $i | awk '{printf "%05d",$i}'`
echo $d
pdftk A=$1 cat A$i output page$d.pdf
pdftoppm page$d.pdf -gray tmp
ppmtopgm tmp-000001.pgm | \
pamthreshold -simple -threshold=0.85 | \
pnmtops -imagewidth=8.5 > tmp.ps
ps2pdf -dPDFSETTINGS=/ebook tmp.ps
mv tmp.pdf newpage$d.pdf
rm page$d.pdf
done
pdftk newpage*.pdf cat output $OUTPUTFILE
rm newpage0*.pdf
rm tmp.ps
rm tmp-000001.pgm
A while back, I investigated the growth of companies like Google and Yahoo, looking at their employee growth versus time. Well, I revisited this recently, and as a few years have passed there is more information to plot!
The image below shows the number of employees at Google versus time. The fit to a logistics function is still quite good! Google has been amusing itself buying companies in areas unrelated to 'normal' Google core areas, so I don't think it will be possible to continue to do this analysis. But if it were, the logistics fit indicates that Google's growth is beginning to slow.
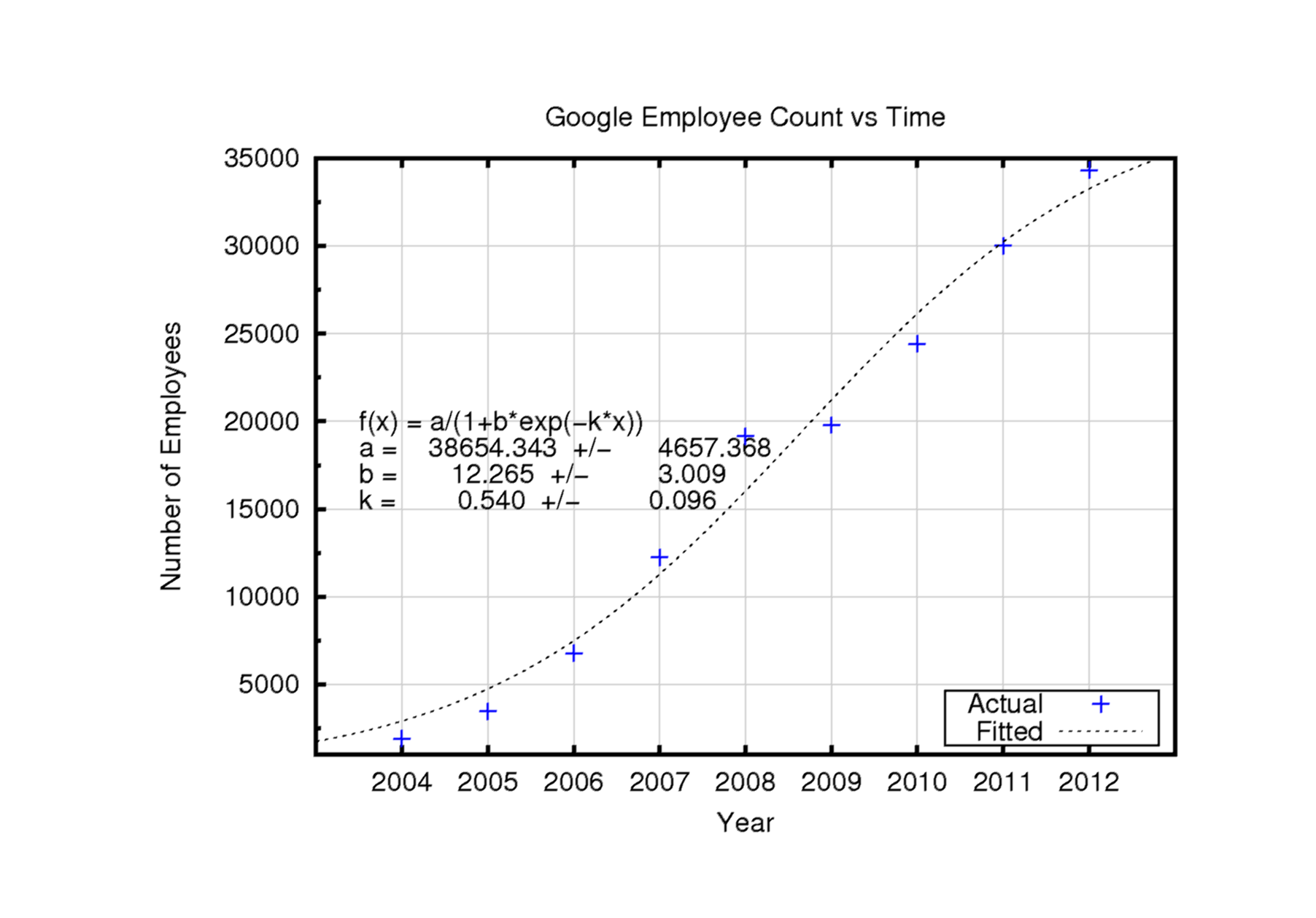
I made this plot using gnuplot. I'll post the script in a future post. I find quasi-technical analyses like this much more straightforward using a command line + data file approach. If I want to replot the information some time after the original work with a new data point (as in this case), I can simply rerun the necessary command (conveniently saved in ascii) and recreat the hard copy. The same operation with Excel or OpenOffice requires multiple mouse clicks and rarely yields the same output without laborious reformatting. And, of course, simple ascii commands and raw data files can be saved in source repositories like cvs or svn for controlled, reproducible, ongoing work.
So it is clearly better to work like this. But, of course, everyone in the world prefers to use Excel and OpenOffice!
I recently posted a scanned version of Bill Shockley's thesis, here. Now scanning a document produces a PDF file which contains simply bit maps of the pages of the document. There is no electronic representation of the words in the document, and so the search function of the PDF viewer does not function. Additionally, web crawlers, or indexing programs for hard drives do not find keywords to index, and so documents are not retrieved when you might otherwise think that they should be in searching operations.
So, I had a look around for methods to correct this situation. I rapidly found pdfocr, which takes apart the PDF file, runs OCR on the images of the file, and reassembles the PDF with searchable text embedded in the file. This sounded good in principle, but there were problems in practice, probably caused by the fact that the packages wihch pdfocr relies on having evolved in the last few years.
However, I found a nice bash script which uses the tesseract OCR package: http://ubuntuforums.org/showthread.php?t=1456756&page=4
The script takes a while to run. But on completion you have a copy of the PDF, of approximately the same size, but with embedded searchable text from an OCR run on each page. This makes your PDF file searchable - with a fair chance of finding important phrases and also indexable by web crawlers and hard disk indexers.