| Su | Mo | Tu | We | Th | Fr | Sa |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
sed is a wonderful tool! There are books, man-pages and generally good resources for sed users online. However, given how useful the tool is - it is hard to master - so I thought I would provide just a little information here.
Say you want to extract the ascii information in an html file for additional processing - how should you do that? Many programs can input html (e.g. aspell used elsewhere here) - and sometimes use the html tags to set font and formatting information. But what if you just want to count characters or words in an html file - how do you proceed? The first step is a quick google to 'sed one liners', and there one finds that the command line required is:
sed -e :a -e 's/<[^>]*>//g;/</N;//ba'
or to do this with a specific file
sed -e :a -e 's/<[^>]*>//g;/</N;//ba' filename.html > filename.txt
But how does this command work? Well, it builds a sed program with two sets (-e) of sed input. The first, :a, sets the branch label to 'a' at the beginning of the sed program. The second command says - if you find a left angle bracket that is followed immediately by any character which is not a right angle bracket ([^>]), and is followed by some characters (*) and a right angle bracket, then globally replace it with nothing (//g). This takes care of <tag> html tags on one line - but what of tags which span lines? Well, they will hit the /</N command which will append the next line into the sed pattern space and then the (//ba) will branch back to the beginning of the sed script (remember the 'a' label?) to continue to the search for the tag to replace with nothing (//g). Simple, elegant and compact!
Do you want to make a local copy of a web site for future reference? (Perhaps your boss has asked you to copy the internet to his laptop, for his convenience, for example). Well, for a specified site, that task is relatively straightforward with wget - which you can easily find on Linux, on Windows as part of Cygwin, and OS X as an add-on.
Here is the synax of the command to download this web site:
wget --mirror -w 1 -p --html-extension --convert-links -P ./ http://wwww.themolecularuniverse.com
The options here are:
'-mirror' get a copy of everything on the site
'-w 1' wait for 1 second for each page - this is optional and reduces the load on the site
'-p' get the prerequisites for the page - this means that linked graphics files, for example, will be downloaded too
'--html-extension' change any files which don't have an html extension to html
'--convert-links' make links in retrieved documents point to their local versions
'-P ./' put the retrieved files into the current working directory
wget can be very helpful...but of course you will just acquire a static copy of the target site and you will not get updates, enhancements, or corrections!
Search engine optimization, or SEO, is a topic shrouded in jargon and folklore. However, its net effect is to mimic the creation of quality online information. A more reliable route to achieving the objectives of SEO is to actually create quality content.
When you look at the you see advertising for Search Engine Optimization, or SEO. In the past I have wondered what SEO was all about, so I conducted some investigation, read several articles, a book or two and in the interests of demystification, I thought that I would summarize my simple conclusions. Search Engine Optimization, as a topic, profession, or activity is firstly hard to define and secondly essentially worthless.
The traditional definition of Search Engine Optimization is that entails two distinct activities. The first is improving the targeting of web pages for specific search terms, so that Search engines such as Google, Yahoo, and Bing, will tend to provide certain pages in response to specific queries. The second is improving the ranking of those web pages among the set of pages which match a given search term.
Why would you want a given web page to be returned by a certain search term? Why would you want a given web page to appear in the first few results for a certain search term? The essential answer is 'readership'. If you have a web page with any form of advertising, be it paid adverts for products or advertising for your own products, you need people to read and see those adverts for the advertising to be effective. One of the best ways to obtain readers, or traffic as it is known on the web, is to be returned for common search terms and to rank highly in the results for those search terms. So SEO is all about obtaining a steady stream of potential readers or buyers.
The first objective of SEO, that of insuring that a given web page is returned as a result for a certain search term, tends to revolve around insuring that key words are appropriately distributed on the target page. Strangely enough, according the SEO folklore, you can have too many key words or too few on a given page. These keywords can be in different positions on the web page and need to be appropriately positioned to have the desired effect. They should be in the header, in the name of the page, in the headings on the page, and generally distributed about the page just as if the page were a piece of normal writing on the subject of the key word.
The second objective of SEO, that of insuring that a given web page is ranked highly in the results for a given search term, is a little harder to engineer. Apparently one effective method is to count the pages in the whole web that point toward this particular page. This is akin to allowing the web to express its collective opinion on the popularity of this particular page. However, again there are good links and bad links. If you have links pointing to a given page from sites which are set up exclusively to create links, this will do you no good. The only sites that get a vote are legitimate, quality sites. The effect is very much as one would see if the page were in fact popular and widely linked to across the web because of its status as an authoritative source of information.
Again, the SEO folklore, warns early and often of the problems of gaming the system. The search engines penalize sites which are guilty of using tricks in order to acquire additional traffic. Only legitimate sites can reliably expect to be highly ranked by the search engines.
This leads to the inevitable conclusion that the important part of SEO is actually creation of quality content. This will not be interpreted as attempting to cheat by the search engines which index the web and so will not be penalized. It also calls into doubt the entire activity of SEO, anything artificial that is done to boost search engine performance can likely be detected by the search engine development teams and then penalized in the future.
So, if you are thinking about SEO as a route to increased web site traffic, think instead of improving your web site's content and its overall quality. This is the tried and tested approach, which is unlikely to fall foul of the search engines' game detection schemes, because it perfectly matches what search engines seek, quality, useful content.
Here are the steps necessary to create and apply categories or tags in NanoBlogger.
First to create a tag, use the following command:
nb tag new add
You will be prompted for the string associated with this cateogory or tag. Enter something like 'bash' or 'politics' (as appropriate) and the tag is created.
Then to list your current set of tags use:
nb tag-list
Each tag has a number and you use the number to assign tags to articles. Now find an article to apply your tag to - the way to do this is to list your current articles:
nb list
Then apply a given tag to a given entry. This is done using the numbers fro your list commands, so to apply tag 8 to entry 6, you would use this command:
nb tag 8 tag-entry 6
And if you want to apply several tags to one entry with a single command, you can comma separate the tag ids:
nb tag 4,6 tag-entry 1
A final nuance is apply tags to entries that are way back in time and therefore have entry ids above 10 (by default 'nb list' only provides access to the last 10 entries). In order to find and tag these entries, you can use the following commands, to find, tag, and rebuild your blog:
nb list query all | more nb query all tag 5 tag-entry 36 nb update query all
That, in a nutshell is tagging or categorizing with NanoBlogger.
This article was written in early 2010 and published by the now defunct Associated Content site. It seems that the issue of what happened to the original climate records managed by the UK Climate Research Unit (CRU) at the University of East Anglia may never be addressed.
The Dog Ate My Homework or the Real Climategate Scandal
It has been interesting to read about the so called 'Climategate' scandal in the press. For those who have not heard, a hacker, or a whistle blower, posted many email messages, and software programs from the UK Climate Research Unit (CRU) at the University of East Anglia on the internet in November 2009.
The messages show that the scientists massaged the charts in their papers (or used a 'trick' as they described it) to support their preferred conclusions, fought and applied peer pressure to insure that reviewers squelched dissenting voices from other workers, and systematically avoided providing their raw data to anyone including fellow researchers. The scientists even sent each other messages requesting that certain email exchanges be deleted, effectively recording that they were engaged in removing who knows what information from the permanent record.
The programs included in the released archive show that raw data was massaged in very arbitrary ways in order to support the warming trend hypothesis favored by these researchers.
There is even a lengthy document which describes attempts to reconstruct previously published temperature information. Unfortunately for the researchers, the lengthy saga described in this document reveals that it was not possible to recreate the data, because nothing of the original massaging had been documented, the original recipe had been lost or forgotten.
All of this was quite a surprise, given that everyone had assumed that the media reports of the general scientific acceptance of man made global warming were accurate.
All of these problems might well be just a few simple mistakes, made over the course of several dazzling careers of excellent scientific work, and nothing much to be concerned about. What is required is an independent check of the information which was maintained by the CRU.
However, it turns out that, just as in Watergate, important parts of the record are missing. Amazingly enough, despite the fact that the cost of computer storage has been rapidly declining, just as the earth has been (apparently) warming, the actual temperature measurements that one would presume that the CRU would jealously guard for the greater good of mankind have been 'lost'. They are no longer available to be generally reviewed. All that is left is the processed information, for which even the CRU employees cannot document the massaging (or 'value adding' as it was termed by the scientists).
The official excuse for this is that computer tapes were lost in an office move. Yet, as anyone with any computer experience will tell you, there is no need for computer tapes to be involved in the storage of important technical data. When originally gathered in the sixties, seventies, and eighties, perhaps measurements were indeed stored on tape. But with each new generation of computer, storage capacities have increased. What once required storage on tape, can now be permanently stored on disk. We have all seen this effect in our own lives. We once had important data on floppy disks. As our computers now possess larger hard disks these days we store that data on hard disk. For a period when we upgrade a computer, we run both of the machines in parallel and transfer the information to the new machines. We are not paid by tax payers to be the custodians of climate research and knowledge; we are just applying basic common sense to the storage of important information.
More than likely all of the original measurements would fit on a 4 GB USB stick. Losing this original record is equivalent to being put in charge of the output of the human genome project, and then accidentally deleting that information.
As we ordinary mortals are also aware, if information is important, we back it up. How would one define important? Perhaps if that information has been gathered at the expense of putting satellites into orbit and manning weather stations all around the world with tax payer's money, in order to generate vastly important raw scientific information, we would judge that as information as important and worth backing up.
Well, we are now being asked to believe, that the CRU experts thought that such precautions were beneath them. No, unfortunately, the original raw data is lost. The journalists and pundits much prefer the calamity message of man made global warming, and treat this lost information as entirely plausible and understandable. The mainstream media, unlike scientists, of course, are well aware that nothing is as valueless as yesterday's information.
Looking back at information rarely causes the reader or viewer to dwell on the latest set of adverts. Looking back at past newspapers, for example, would soon show that the dire climate change predictions of the 1980s did not come to pass. And the global cooling calamities of the 1970s are completely lost in pre-history. No newspaper should ever mention these old stories which used to fill so many column inches, for fear of devaluing today's scare stories.
So the media cannot be faulted in ignoring the accidental loss of the climate data. The scientific community, like a group of doctors unwilling to cast aspersions at one of their own who has killed one patient too many, are also silent. Politicians, never apt to waste a good crisis, are as always calibrating the chances of their maneuverings with respect to the interests of increasing governmental control, or gross capital transfer to the wealthy (depending on their hue) coming to light before the next election.
But people in general are beginning to have a sense of the potential problem. It is quite clear that the CRU 'team' have made mistakes. An organization set up to be the custodian of vital scientific information has lost and corrupted that information. And in the absence of openness and clarity it has opted for a 'The Dog Ate My Homework' excuse as a feeble attempt to avoid scrutiny. Such a phrase typically fails to impress good school teachers. However, the climate expert professors appear to hope that this will be sufficient to dupe the public and politicians.
Fortunately people in general are now able to find their own information and form their own opinions. The information leaked or hacked from the CRU is now freely available on the internet, where it should have been all along. (Just google for FOI2009.zip). Have a look at the files, whether you are a climate change proponent, skeptic, or above such labels, you will see that the media reports are astonishingly trusting of the CRU and its scientists. You too will wonder where the original temperature measurement information is, and you too will be amazed to find that anyone could consider fobbing you off with 'The dog at my homework - but believe me anyway - I am a scientist'.
Seems a little convenient and cynical to me - and yet there seems to be a good chance that the CRU 'team' will get away with it. Now that is a real scandal.
Source:
Freakanomics Blog NY Times, 11-November, 2009: http://freakonomics.blogs.nytimes.com/2009/11/23/climategate-the-very-ugly-side-of-climate-science/
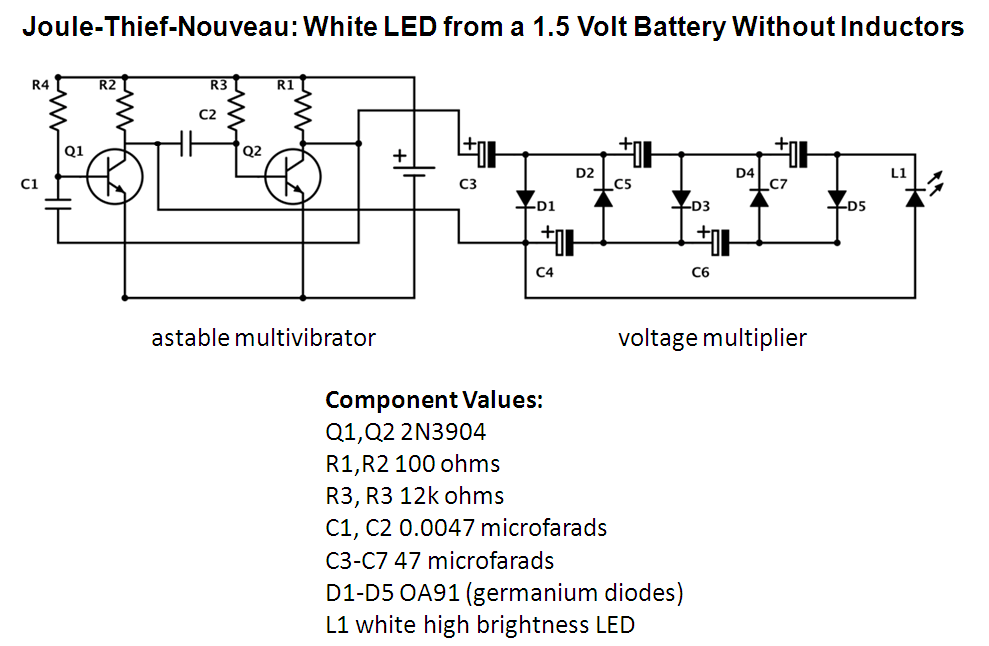 |
The traditional Joule Thief circuit employs an oscillator to generate an increased voltage from a 1.5 battery in order to drive a LED. The Joule Thief circuit is very widely circulated on the web, it contains few components, and can light a LED with a single battery for many hours.
Why is the Joule Thief circuit popular? A white LED needs something like 3 volts in order to light up. A normal battery cell provides 1.5 volts, so some circuitry is required to light a LED with only one cell. The Joule Thief circuit is simple (it uses 4 components) and efficient.
The Joule Thief increases the voltage seen by the LED by allowing a magnetic field to induce a current in a transformer. By suitably choosing the coil a significant step up in voltage can be obtained.
An alternative voltage increasing strategy is provided by using a capacitor to store charge, then switching the capacitor to be in series with the battery, effectively doubling the battery's voltage. Given appropriate switching controls, this method for increasing voltage can be very efficient, but it requires significant circuitry in order to carry out the switching.
However, as an experiment, I recenly created a circuit which lights a white LED using a single cell and a capacitor based voltage doubler network. The circuit is shown above, if you click on the image you should see a larger version. This circuit simply feeds a voltage doubler network using an astable multivibrator. The diodes in the voltage doubler must be germanium diodes, because these diodes have a forward voltage drop which is much smaller than a silicon diode.
Although the circuit works, it uses many more components than a Joule Thief circuit, and it is not as efficient! Nevertheless, I will probably make myself a flashlight based on the circuit at some point - I simply want to have a device which uses a voltage doubler network in my pocket!
The component values are not especially critical. However, it is essential that the diodes in the voltage doubler network are germanium. (I am calling it a voltage doubler network - but actually it quadruples the voltage supplied by the multivibrator which just gets the voltage up to the level required by the LED. This is because when a transistor switches on it does not conduct perfectly and there is the 100 ohm collector resistor which drops some of the voltage, so only about +/- 1 volt is presented to the voltage doubler network. Nevertheless, it does work and uses relatively few components, so that it is accessible for simple experimentation.
So, if you are ready for an interesting conversation piece flashlight (or torch depending on you linguistic predalictions) - build a Joule Thief Nouveaux!
I don't pay all that much attention to politics. My thinking is that it is overly simplistic to try to divide all possible policy issues into two groups, and then simply select the preferred group as your purveyor of all desirable results. So, I tend to prefer the 'left' perspective on some issues and the 'right' perspective on others.
I also tend to prefer to keep matters to be based on facts. As do scientists and historians - the reasonable ones at least. Recently I have been tending to read two particular 'cultural historians' for their perspectives on recent political developments. My theory is that these historians should at least get the facts straight.
Representing the left is Alwyn W. Turner, who claims to have accurately predicted the recent UK electoral outcome. Alwyn writes a great deal about the recent history of the UK, using his encyclopedic knowledge of popular cultural at every turn. His recent writings on the UK general election have been very entertaining ('...or that bloke up in Scotland, whose constituency is so remote that not even SNP canvassers could find it.') and provide great insights into the defeat of the Labour party.
And representing the right is Mark Steyn, who claims to defend free speech, and the right to poke fun at climate scientists. Mark's knowledge of music and musicals is encyclopedic, and even if you don't much care for Broadway, after reading a witty 10,000 word essay on Mark's blog, you will have a passing acquaintence with the historical emergence some obscure numbers, and will be able amaze your friends by describing the song's lyricist, composer, and the various perfomers who have covered the song through the ages.
Turner and Steyn poke fun at their own political favorites. Turner called out the Labour party for fascillitating male/female segregated meetings, and Steyn does not suffer the right's slip-ups gladly (see for example the folding expertise of the republicans dealt with here.
Their similarities caused me to wonder if it might not be possible to find similar left/right writer pairings with additional interests and then set up a pages of links providing access to the left and righ opinion on issues. It is straightforward to find biased sites these days - everyone who attended journalism school seems to have forgotten about reporting the facts - but I wonder if there is an interest in a site which attempts to collect the balance of perspectives?
If there is, here is a first entry:
Cultural History
I wonder what the entries should be for chemistry, economics, banking, etc. I will give it some thought...!
The following bash script is useful - if you want to see if you have differences between files in two sets of directories trees on different machines.
It is not terribly sophisticated. It does not use any significant network bandwidth to do the comparison - because it uses a checksum calculation on each machine. It has two arguments. The first is the servername or the username@servername couplet depending on how you have set up your sshd's and so on. The second argument is the pathway to the directory that you want to compare with the current directory on your current machine.
All the script does is collect a set of sorted checksums on your present machine starting at the current directory, collect a similar set on the remote machine at the specified location, and then diff the two sets of checksums. If the directory trees are identical there will be no differences and you will be told this. If there are differences you will see the differing files in the output from the diff command.
As you can see the script is not really recursive, it simply uses find to collect all the files. However, the effect is that of a recursive directory differencing across a remote machine's directory, without consuming significant bandwidth.
#!/bin/sh
#provide a simple, remote directory diff based on checksums
echo "arg1 is the username and host, e.g. user@server ": $1
echo "arg2 is the remote directory, complete path": $2
ssh $1 "cd $2; find . -exec cksum {} \\;" | sort -k3 > /tmp/dir1.txt
find . -exec cksum {} \; | sort -k3 > /tmp/dir2.txt
diff /tmp/dir1.txt /tmp/dir2.txt
ret=$?
if [ $ret -eq 0 ]
then
echo "The directories are identical"
fi
The Molecular Universe site grew out of talks for schools. The talks generated text and graphical material and this formed the topics in the main part of the site. As often happens, work was put into the site inconsistently and the site languished for a number of years. I am now trying to improve that situation...(as they say). Initial work to write and collect pages for the site was done working with a distinguished collaborator. Subsequently, on occasion, I created new articles about molecules, chemistry, and materials science, and these articles formed parts of the blog system.
Mostly the site has been 'for fun'. Although the site has adverts, they generate far less than it costs to host the site. But it is an interesting activity and I hope somewhat informative site, and so I have kept it going.
Now I figured, why not move it forward?!
So, to do that, here is a basic outline of what I intend to do:
Well, that is the plan. We shall see how it goes.
 |
In October 2014 using the cumulative death figures from the terrible West African Ebola outbreak, I fitted a four parameter logistics function to the data using Excel. This is straightforward to do using Excel's 'Solver' functionality, you set up the squared residuals, sum them, and use the solver to adjust the parameters to set the sum of squares to zero.
The resulting fit indicated an eventual cumulative total death toll of 9,216 people. The logistics function assumes that the response to growth is proportional to that growth in the end, and that is a good basic description of the growth of bacterial colonies and so on. In the case of the Ebola outbreak, the death toll is no doubt reduced by the fact that preventative measures are taken, and this is also in some measure related to the rate of growth, so the logisitcs function can describe this system.
I have included in the image information on how to set up the necessary formulae to create this ultra simple model. If you follow the link in the image below you will reach a larger version of the image.
This was done in October 2014, approximately 7 months ago. The current total death toll, according to this CDC site is 10,980, so the prediction was not catastrophically wrong. Basically, the logistics function says that the tail off after the maximum increase is seen will be similar to the ramp up when the disease first gets a foothold.
I like the logistics function! See the following links:
Companies and Bacteria
Company Growth